![]() Alexandre Bouchard
Alexandre Bouchard
How We Built a Rate Limiter for Outbound Webhooks
We built Hookdeck with one goal in mind: free developers from the burden of assembling their own webhook infrastructure by providing a reliable, ready-made alternative. If we were going to accomplish this task, the first step would be to build a robust queueing system that would allow our users to process webhooks asynchronously at a predetermined rate.
We wanted to avoid tampering with the inbuilt simplicity of webhooks, namely the straightforward HTTP POST request. With this requirement in mind, we set out to build a configurable "Push" queue that each user could adjust to their individual use case and infrastructure capacity.
What follows is a write-up of how we built our system. We hope this serves as a helpful guide so that, when it’s your turn, you don’t have to reinvent the wheel.
A Peek into Hookdeck: Events & Attempts
Let's take a step back and take a look at some Hookdeck semantics.
Each webhook request ingested in Hookdeck results in one or more Events for each destination (aka: endpoint), as configured by the user. An event can have multiple Attempts, each of which represents an outbound request to a single endpoint.
These attempts are precisely what need to be throttled. Historically, we would simply queue those attempts and have our HTTP delivery service pick them up concurrently, and execute the requests.
But going forward we needed to ensure that, at any given time, the correct number of requests would make it into our attempt queues. These queues would need to adhere to the differing rate limiting requirements of each destination configuration. Simply put, we needed an intermediary step.
Challenges & Requirements
- In Hookdeck, each user can have multiple destinations (HTTP endpoints) with different use cases. We wanted the rate limiter to be adjustable per destination, which could potentially result in thousands of different rate limits.
- We wanted to offer both per-minute and per-second rate limits.
- We needed these limits to be dynamically adjustable, such that updates to the rate limits could propagate quickly throughout the system.
- We needed to support redundancy and horizontal scaling to ensure high reliability.
One thing was painfully clear from the start: maintaining a queue and a consumer for each destination was not going to be viable. Thousands of queues and consumers would be impossible to scale horizontally. If we wanted to add redundancy, it’d introduce the issue of synchronization. With multiple consumers working through the same queue, while targeting a dynamically changing rate limit, we’d need to synchronize them in lock step – and yet they’d need to be able to adjust on the fly when one inevitably died.
That’s a hell of a lot of things that can go wrong. We needed a different approach.
Architecture
How could we build this queueing system without employing N queues? By queuing and consuming jobs on a schedule.
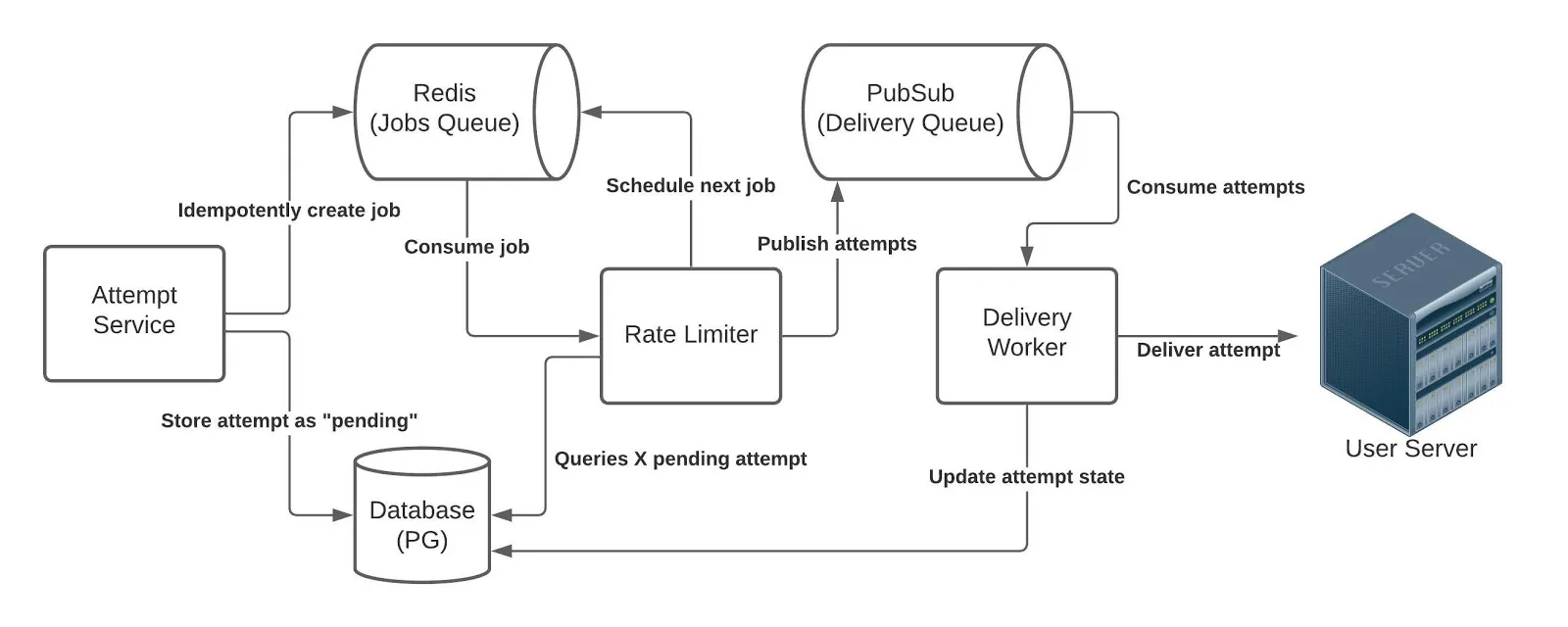
Rate Limiter Jobs
A rate limiter job is a message published for a destination_id and with a delay . The rate limiter service consumes these jobs as soon as the delay expires and proceeds to:
- Query the most recent rate limit value for that destination.
- Queue the next job with the appropriate delay.
- Query X attempts in accordance with the rate limit.
- Publish X attempts to the delivery queue.
The delay is a function of rate limit configuration. A per-minute rate limit period is translated in req/s.
{
let rate_limit = rate_limit || 0;
// default to 'second' if NOT 'minute'
if (rate_limit > 0 && rate_limit_period == 'minute') {
const per_run = Math.ceil(rate_limit / 60);
delay = 60 / (rate_limit / perRun);
rate_limit = per_run;
}
In our case the delay, implemented using Redis ZSCORE, is really just a future timestamp. In order to avoid introducing unnecessary delays we also remove the time that the function has taken to execute up to that point – generally it's around 10ms, with most of that time coming from the query to fetch the current destination’s rate limit.
The Delivery Queues and Workers
With this approach, any attempt in the delivery queue needs to be delivered ASAP. Otherwise, the delivery queue might become a rate-limiting factor in itself – or, worse yet, cause a violation of the rate limit rules by delivering attempts sporadically.
To ensure prompt delivery, we scale the workers horizontally based on queue depth using Kubernetes HorizontalAutoScaler and GCP metrics.
Short Circuiting
In order to guarantee we won’t exceed the rate limit, we need to account for unexpected behavior further down the flow. What happens if the delivery workers crash for some reason, or fail to keep up with the delivery queue because of a database error? How can we prevent attempts from piling up? And, given that we need to deliver events in the delivery queue ASAP, how do we guarantee throughput once we recover from an error?
The solution is to short circuit the rate limiter. The actual formula for determining the number of attempts to push is:
const allow_attempts_count = rate_limit - attempts_still_in_queue;
When everything is going fine, the attempts_still_in_queue should be 0 at every job run. If anything goes wrong the rate limiter will adjust accordingly and only publish the remaining buffer. At any given time the delivery queue cannot contain more attempts than the rate limit.
When short circuiting, the rate limiter schedules a new job without publishing any attempts.
Shutdown and Restart Per Destination
Because of the sheer number of destinations, running jobs for each one every second or so would be wasteful. Instead, we gracefully shut down by deleting the most recently queued job once there are no longer any attempts left to process. Whenever a new attempt is created we idempotently queue a new job to restart the process.
Redundancy and scaling
Because we rely on a small number of queues, introducing redundancy and scalability becomes trivial.
We build each of those services into a docker container that's deployed on Kubernetes (GKE) with multiple pods per deployment. Each one is configured to scale in accordance with the depth of the queue.
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: pubsub
spec:
minReplicas: 2
maxReplicas: 20
metrics:
- external:
metric:
name: pubsub.googleapis.com|subscription|num_undelivered_messages
selector:
matchLabels:
resource.labels.subscription_id: SUBSCRIPTION_ID
target:
type: AverageValue
averageValue: 0
type: External
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: delivery-workers
Testing and Auditing
To ensure the rate limiter is stable, doesn't introduce excessive latency, and fully abides by the rate limit, we introduced an essential metric on the attempt. delivery_latency measures the ms between creation and delivery of each attempt.
Lastly, a simple SQL query will give the distribution of attempts made per second. By comparing those per-second values with the destination rate limit, we can confirm that the limit wasn't exceeded at any given point in time.
SELECT
date_trunc('second', delivered_at) as date_sec,
count(id),
round(avg(delivery_latency) / 1000) as latency
FROM attempts
WHERE
delivered_at is not null
GROUP BY date_sec
We can simply spin up the rate limit, bombard it with attempts, and compare the results!
Results
We now have a fully redundant and horizontally scalable delivery infrastructure using Kubernetes HorizontalAutoScaler and GCP metrics. Any one pod dying will temporarily reduce our total capacity – but it won’t impede our ability to process messages.
For our users, that means you can set and update a given destination’s rate limit dynamically with a simple change in the dashboard.
Looking forward: Smart Delivery & Backlog Alerts
While we’re proud of what we’ve built, it's far from over.
In a future release, we hope to introduce a "Smart Delivery" algorithm that will automatically adjust the rate limits of users’ destinations based on the variance in response latency and error codes. That means you’ll be able to skip the time-consuming work of determining optimal throughput values by allowing Smart Delivery to crunch those numbers for you.
Additionally, we know we need to grant visibility and control over the backlog of attempts. In cases where the queue grows very large, users may want to know about it and take action on those attempts. We hope to help with that, too!
Try Hookdeck for Free
There’s an endless list of features and improvements we’d like to build, but every improvement must be built atop a foundation that is robust, reliable, and user-centered. Our webhook infrastructure is just that.
With Hookdeck, you can easily set up and monitor your webhooks without worrying about ingestion, queuing, or troubleshooting processes in your workflow. And it’s free!