![]() Fikayo Adepoju Oreoluwa
Fikayo Adepoju Oreoluwa
Why Kafka Might Be an Overkill for Your Webhooks
Webhooks are events, and the recommended way to handle these events is through asynchronous processing. The key component in asynchronous processing is a message queue, and one of the best options in this regard is Kafka.
However, when dealing with webhooks Kafka might be an overkill due to its costs and complexity. While Kafka’s capacity and performance are tempting, other factors lead to the costs outweighing the benefits. These costs are what we’ll discuss in this article.
Processing a webhook
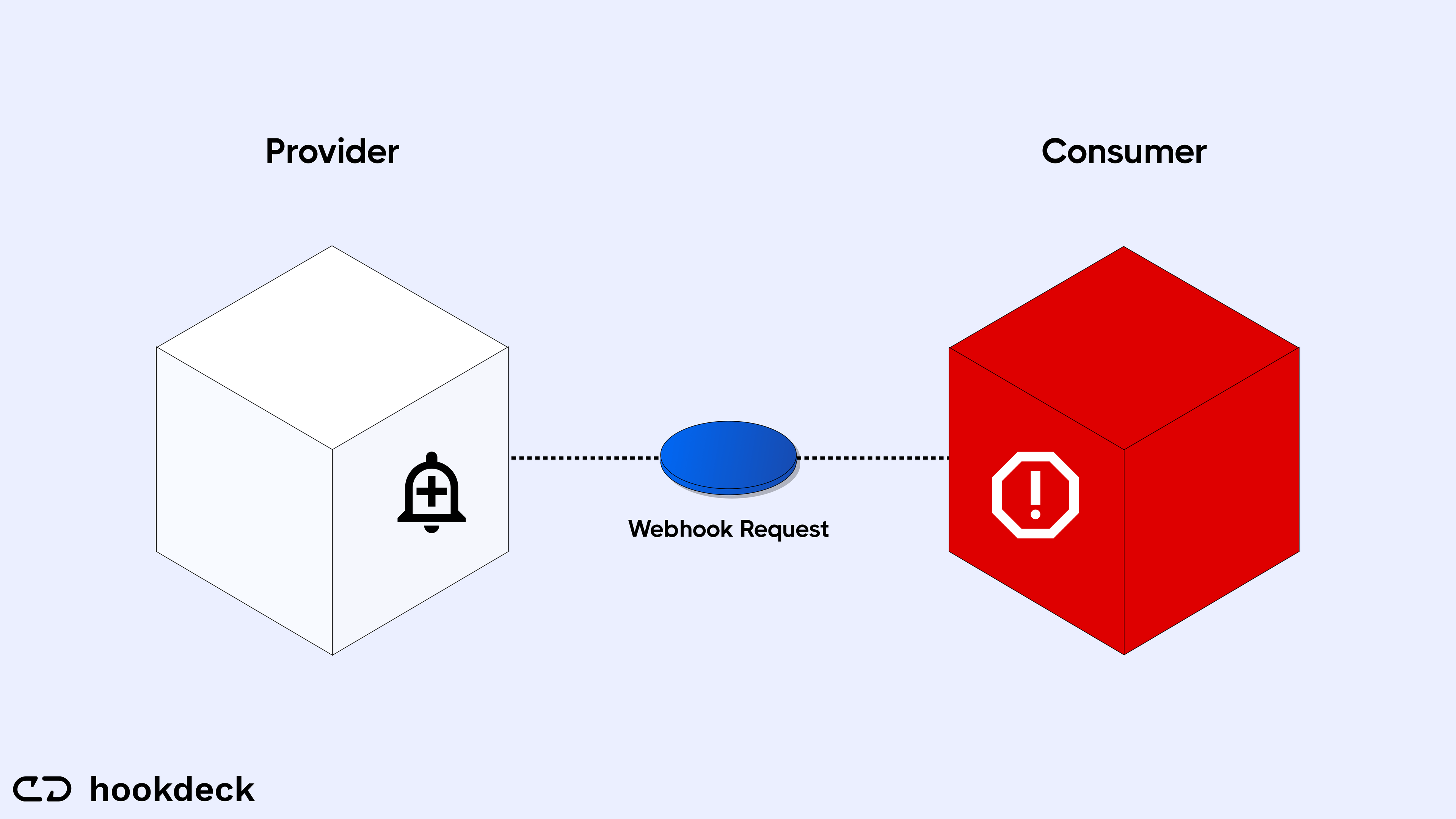
As seen in the image above, a webhook creates a simple communication pipeline a webhook establishes between a producer and a consumer. An event occurs in a producer; the producer fires a webhook (an HTTPS request) to the consumer, and the consumer processes the webhook. Easy, right?
However, the experience of implementing and maintaining these webhooks in a production environment is not so simple. A lot can go wrong within the communication process, which includes but is not limited to:
- High latency causing webhooks to be dropped
- Network failure
- The server shutting down due to overload, migrations, or routine maintenance activities.
- Buggy releases
- …and so on.
These and many more factors can compromise the communication pipeline and lead to the loss of information, which explains the need to implement webhooks to be reliable.
For more information on problems that can you can run into with webhooks, check out our "Webhook Problems” series.
Doing it reliably
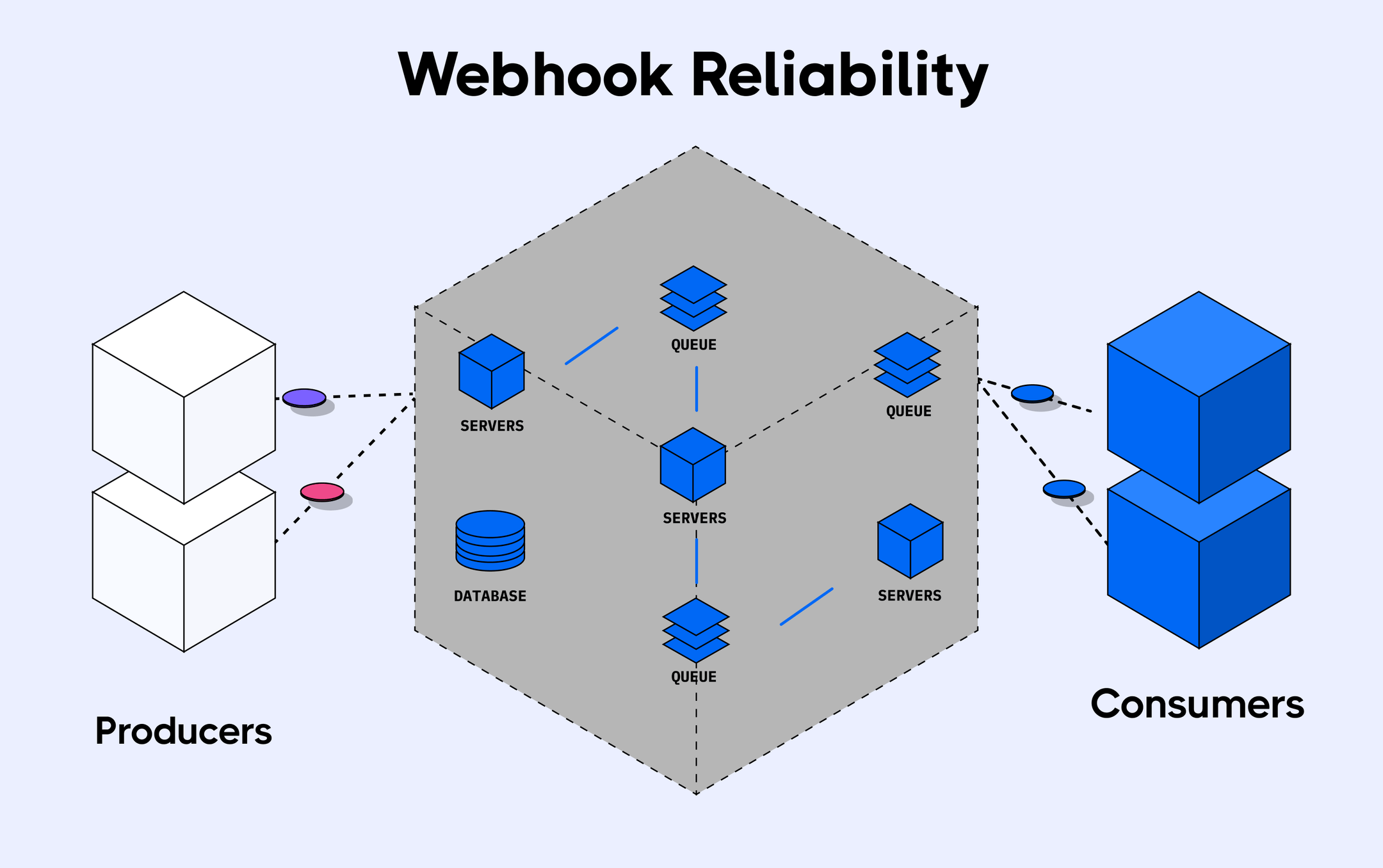
Now that we understand the brittle nature of webhooks in production, let's start by establishing what is required to implement webhook processing reliably through asynchronous processing. The requirements are:
- A producer to receive webhooks runtime to add messages to a message queue
- A message queue
- Consumer runtime for processing the webhooks
- A retry mechanism for failed webhooks
- A rate-limiting component for throttling webhook delivery
- Instrumentation and visualizations for monitoring and alerting on webhook activities
- Fault tolerance through horizontal scaling
Let's now look at how Kafka may not be the best fit for a simple and lightweight event-driven architecture like a webhook.
Performance comes with complexity

Kafka is built to handle trillions of data. This power comes at a cost that might be overwhelming for a simple use case like webhook communication.
Kafka requires clusters to be set up, as well as detailed capability planning, complex integrations, complex troubleshooting, distributed ingestion runtimes, distributed consumer groups, and more. It gets to a point (pretty quickly) where all these complexities outweigh the benefits.
Most webhook use cases are not trying to process billions and trillions of data, which is the scale Kafka is designed to handle. Most developers and teams from small- to medium-scale startups do not require this much capacity and will do better with a plug-and-play solution that guarantees reliability.
Imagine an e-commerce store with an average of ten thousand (10,000) visits a month, which translates to one thousand (1000) sales. This seems like an active store, and if we assume 3 webhooks fired for each sale, that’s a total of 3000 webhooks/month.
It would be overkill for this store to invest in a complex and expensive Kafka processing setup that can process millions of webhooks per second when they rarely receive up to a hundred concurrent webhooks, even at peak periods.
The learning curve required for setting up Kafka for webhooks
Another challenge of implementing Kafka for webhooks is the level of expertise it requires to set it up. Here are a few of the concepts and technologies you will need to be proficient in:
- Event-driven architectures
- Distributed systems
- Message queuing in general
- Kafka itself
Is it worth learning all these or hiring an expert (which does not come cheap, more on that later) when all you need to do is set up an integration between a SaaS application and your app?
Seeking the expertise will also vastly increase your time to value on integrations or cost you a lot of money.
While this may be justifiable for companies that need the data processing capacity of Kafka (wherein up to billions and trillions of webhooks can be processed) and who can either pay for or have the expertise in-house, the cost outweighs the benefits for others.
Roll-your-own management
Because of the amount of data that Kafka is expected to handle, Kafka's design is lean in the responsibility department.
This means that Kafka does a few things exceptionally well while deferring other responsibilities to its producers, consumers, and external components like Zookeeper. As the developer, you have to pick up these responsibilities, which include:
- Retrying webhooks
- Monitoring instrumentation
- Monitoring visualization
- Setting up alerts for important/actionable events
- Troubleshooting and debugging when things go wrong
- …and so on.
Having all these responsibilities thrown at you when all you want is to receive webhooks reliably doesn’t help make Kafka appealing, even with all its power.
Example: Consumers do a lot of heavy-lifting
Kafka follows the principle of “dumb broker, smart consumer”. This means that the consumer must handle any intelligence required in the interactions between the consumer and the broker. Kafka makes no provision for this.
For example, Kafka doesn't push messages to consumers, the consumers have to poll the messages themselves.
Again, Kafka doesn't keep track of the webhooks read by the consumer. Consumers have to keep track of the messages read by decrementing the message offset.
Also, Kafka does not replay a webhook when a consumer fails to process the webhook. The consumer, once again, must change the message offset to replay the failed webhook.
Setup costs
Kafka's setup costs can be divided into the following categories:
- Expertise required: Kafka is non-trivial; thus, you need the expertise to set it up correctly and optimally. In the section above, we described the learning curve for setting up Kafka reliably for webhooks. Such knowledge is mostly held by senior software architects and senior DevOps engineers. According to Glassdoor, the average salary of a Senior architect is around $191k/year, while that of a Senior DevOps engineer is around $163k/year.
- Person-hours required: It takes considerable time and effort to design, estimate, develop, and thoroughly test a Kafka messaging setup. At best, the most experienced engineers will still need at least a day. The typical turnaround time for setting up Kafka for webhooks in a team that has the expertise is around 1-3 days (again only Kafka, without the tackling monitoring, recovery, or the requirements).
- Infrastructure costs: Kafka requires a cluster of servers to be set up, so you'll need to invest in networking equipment such as switches, routers, and load balancers to ensure high availability and fault tolerance.
- Operational and maintenance costs: Kafka is a complex system requiring day-to-day tasks to keep it up and running. You will also require monitoring and support, which you'll have to train or hire staff to perform. The cost of engineers you will need may not be a one-time thing as you still need them on ground to put out fires and keep the system running optimally.
Recently, tech giant Basecamp, alongside its child company Hey, had to quit the cloud after noticing a $ 3.2 million bill even after extreme efforts to keep the cost low. While this is an extreme case, it shows how the cost of maintaining infrastructure in the cloud can run up quickly. Sometimes the cost goes up due to over-scaling. Cost management on services like AWS is a big enough topic to be considered a standalone course. Now couple this with $160k - $190k for at least one engineer capable of handling the setup and a turnaround time of 1 - 3 days.
It becomes apparent that deploying Kafka for webhook integrations is a costly overkill for most teams and use cases.
Takeaway
From all that has been discussed so far, we can see that while it is possible to implement Kafka for webhooks, the benefits come at the cost of complexity.
This cost may not be worth it for most teams working with webhooks who want to integrate with third-party SaaS with quick time to value.
Conclusion
In this article, I have highlighted the considerations you need to take into account as you consider Kafka for your webhooks. However, the main question here is… is it worth it?
That's why we recommend Hookdeck for the quickest time to value on your webhook integrations and management. You can check out this article for a detailed comparison of Kafka and Hookdeck for handling webhooks.
Happy coding!