![]() Alexandre Bouchard
Alexandre Bouchard
Enhanced Webhook Delivery Retry Configuration

Retries have been a cornerstone of Hookdeck since day one. In the unpredictable landscape of event delivery, where network issues and server downtime are inevitable, retries ensure that your critical data isn't lost due to temporary failures.
We've listened to your feedback and are thrilled to introduce several improvements to our retry system. Let's dive into each enhancement and explore how they can benefit your webhook management:
What's New
Second-Level Precision
Retries now support second-level granularity, allowing for more precise timing control. Retries were previously rounded to the nearest minute, but that's a thing of the past. Retries are now precisely scheduled down to the second and support down to 1-second intervals.
Status-Based Retry Rules
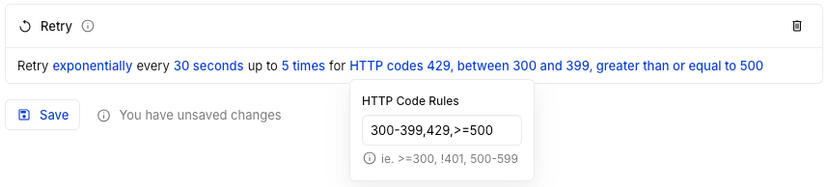
The retry rule can now be configured to apply to specific HTTP response status codes. This allows for more nuanced control over when retries are triggered.
Not all failures are created equal. Some HTTP status codes indicate temporary issues, while others suggest permanent problems. Status-based retry rules let you tailor your retry strategy to different scenarios.
Example: You're integrating with a third-party API that sometimes experiences temporary outages (500 errors) but also has rate limiting (429 errors). You can set up a retry rule to handle these cases differently:
The status codes support inclusion, exclusion, ranges, and greater than/less than comparisons (>=, <=, >, <). For example, to retry all 5xx and 401, you can use >=500-599, 401.
The API Retry Rule has a new response_status_codes property, and the dashboard has a new Response Status Codes to set the status code ranges.
x-hookdeck-will-retry-after header
We've added a new x-hookdeck-will-retry-after header to the HTTP request made to your destination, providing visibility into upcoming retry attempts.
This header indicates the number of seconds the next retry will be scheduled in once your server responds, assuming a retry is applicable. If there's no x-hookdeck-will-retry-after then the request is the last automatic retry that will be made.
POST /webhook HTTP/1.1
Host: your-server.com
x-hookdeck-will-retry-after: 120
Retry-After support
Hookdeck will now adere to the Retry-After header if returned by your destination response.
This can be useful for implementing custom retry logic or scheduling retries based on specific errors. The Retry-After header must be an integer value representing the number of seconds to wait before retrying the request, a valid date string as per the HTTP spec, or an ISO string.
On top of that, the Retry-After header can be used to cancel any further automatic retries by returning a value of -1.
Other Improvements
- In the dashboard, your latest retry rule is now persisted as your new default when creating a new connection or adding a new retry rule.
- The retry rule is now inclusive rather than exclusive. For example, if you set 5 retries, you could get up to 6 total delivery attempts. Don't ask why that wasn't already the case, we don't know either.
- The default retry rule in the dashboard has been updated to retry 5 times with an exponential strategy with a 30-second interval.
Check out the retry docs for more information.
Behind the Scenes
These enhancements to our retry system are, in part, possible due to a new architecture to handle scheduled deliveries, either because of a retry or delay rule. Our previous approach relied on cron jobs, which is why the system was limited to 1-minute intervals.
The new architecture uses timers with millisecond precision implemented as a Redis SortedSet where the score is the timestamp of when the event should be delivered.
However, because Hookdeck is stateful and retries can be canceled for many reasons, the timers either needs to be canceled or, in our case, scheduled "just-in-time".
Event timers are scheduled up to 2-minutes in advance and every minute, a job is triggered to hydrate the timers for the next 2 minutes. This ensures that we only have at most 2-minutes of timers in Redis, making it fault tolerant and preventing runaway memory usage because of large number of scheduled events.
Lastly, because this is not inherently idempotent, once the event is retrieved from the sorted set, the score (scheduled delivery time) is compared with the event's latest state to ensure it's still scheduled to be delivered. If not, the timer is discarded.
This new architecture is much more precise and efficient and opens up the door to new features like the Retry-After header.
Looking Forward
We're eager to see how you'll leverage these new capabilities in your projects. As always, we welcome your feedback and questions. Please don't hesitate to reach out and let us know how these improvements are working for you.