![]() Alexandre Bouchard
Alexandre Bouchard
Experimenting with GPT-Generated Filters
It wouldn’t be 2023 if the Hookdeck team weren’t experimenting with AI or, more specifically, LLMs. At this point, we have to face the obvious fact that our work will change. Specifically, what gets me most excited is that the kinds of products we can build will broaden. So that’s why, on a Sunday night, I embarked on a quest. Could GPT write Hookdeck connection filters on behalf of users? Spoiler alert: it can, faster than I ever could.
What’s up with Hookdeck filters?
Our filters use a custom, open-source syntax cleverly named simple-json-match. I hear you…why did we create a new syntax? As it turns out, all the libraries we looked at focus on schema-based matching (validation) rather than value-based matching. In the context of Hookdeck, users are interested in filtering on the value (content) of the data rather than its structure, so we designed a syntax to get the job done fast.
For instance, if you receive a Stripe webhook with the data below and you want to filter on type customer.created, it would be as simple as that.
// Webhook body
{
"id": "evt_1MhUT6E0b6fckueSqWR0Bec4",
"object": "event",
"api_version": "2022-11-15",
...
"type": "customer.created"
}
// Filter
{
"type": "customer.created"
}
Hardly something you need a soon-to-be overlord AI to write.
However, as with all things, it can get tricky. Over time, users have become more and more intricate in what they filter. It turns out there’s a lot of value in that. To support this, we added more and more operators and features to our syntax to support this use case, but that also made it more complex, when complex filters were required.
For example, an orders webhooks where we want to trigger an action if the order is from either Customer A or Customer B with a price over $100.
// Webhook body
{
"orders": [
{
"order_id": "1",
"customer": "A",
"price": 20
},
{
"order_id": "2",
"customer": "B",
"price": 120
}
]
}
// Filter
{
"orders": {
"$or": [
{
"customer": "A"
},
{
"customer": "B"
}
],
"price": {
"$gte": 100
}
}
}
GPT to the rescue?
Between theory and practice lies a hard-to-cross chasm of dead “innovative” ideas. On that Sunday afternoon, that’s what I set out to resolve. Could we leverage GPT into a real value-added feature that’s production worthy, and how complex would it be?
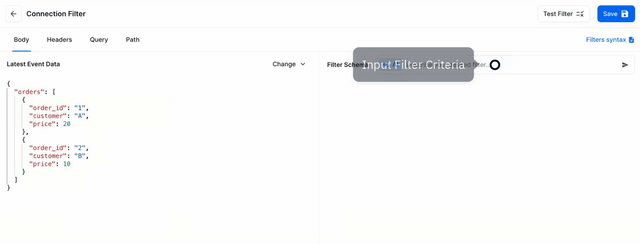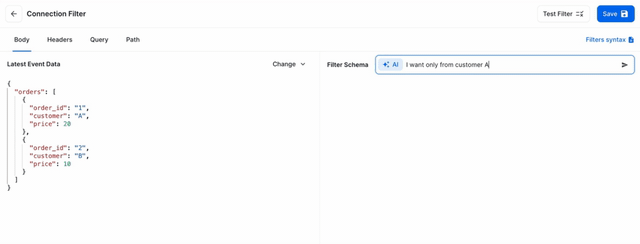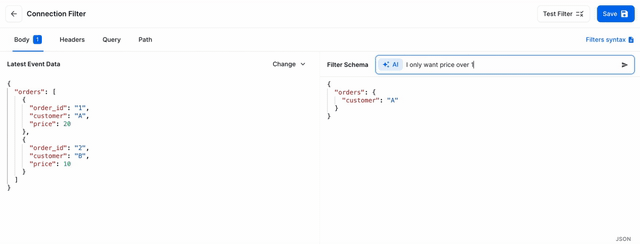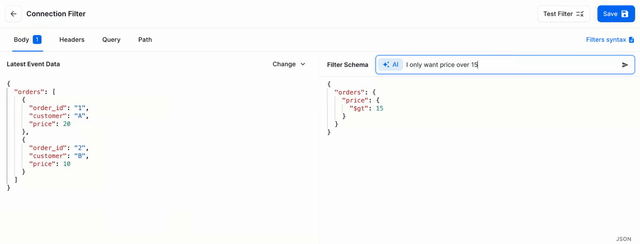
It wasn’t without hiccups, but within 4 hours I had a production-ready PR ready for review. On Monday, it was live in production. Let’s take a peek behind the curtain and look at how it works.
How it works
“Teaching” GPT 3.5 our syntax and getting a filter back
Hookdeck filter syntax didn’t exist in 2021, and GPT doesn't know how it works. I can’t blame it. It’s not like it has a million downloads a month.
Regardless, when it comes to “teaching,” you can’t really do that. In OpenAI GPT “Chat” models, you give context using the system prompt, and that one message is your opportunity to teach the model. Luckily, we already had documentation for the filters written in markdown, so all I had to do was pray that our documentation was good enough that the all-mighty could make sense of it. After trying a couple of prompts, it looked like we did a decent job.
We loaded the system message with the context that we wanted the system to generate a filter and pass the JSON syntax markdown.
From there, we were able to pass a user query within a prompt describing the desired filter.
import { Configuration, OpenAIApi } from "openai";
import filters_documentation from "./filters-docs.md";
const configuration = new Configuration({
apiKey: "OPENAI_TOKEN",
});
const openai = new OpenAIApi(configuration);
const prompt = `Answer with the correct Hookdeck filter syntax using the JSON syntax as described bellow. \n ${filters_documentation}`;
const completion = await openai.createChatCompletion({
model: "gpt-4",
temperature: 0,
messages: [
{ role: "system", content: prompt },
{
role: "user",
content: `
Write a filter to: ${user_input.trim()}
IMPORTANT: Answer only with JSON and absolutely nothing else.`,
},
],
});
Generating good quality filters
After experimenting with the crude approach above, the filters returned by the model were pretty bad. It lacked understanding of what it was trying to write a filter against. Sure enough, although it technically knew about our syntax, it didn’t really understand what the data it was trying to filter looked like since it’s different for each user, and even each webhook.
After experimenting, I found out that by giving it the sample of the data along with the prompt, the output dramatically increased in quality. So much so that I was astonished by every single prompt I wrote. That sounds good, but it introduced a huge problem: token counts, my newfound nemesis.
{
role: 'user',
content: `Using the following input:
${data}
Write a filter to: ${user_input.trim()}
IMPORTANT: Answer only with JSON and absolutely nothing else.`,
}
Up until that point, I had been cheating. I “borrowed” a friend’s GPT4 API tokens which allows up to 8k tokens. However, that’s really not practical. First, I’m not sure he’d be super keen on paying our bill, but second, the model is slow and expensive. I needed it to work with gpt-3.5-turbo and its 4k token limit for this to be production ready.
Giving the model a sample of the data resulted in an enormous token count. JSON is an absolutely awful way to encode content that’s token efficient.

We’re asking GPT to work on JSON data with a JSON syntax. That’s a problem, one that can be fixed by tricking the model into thinking in YAML instead, which uses almost 50% fewer tokens to represent the same structure.

So from GPT's point of view, we’re working with YAML now. All JSON gets converted to YAML before being inserted in the prompt. Impressively, this change worked flawlessly, generated the same quality of filters, and could fit comfortably under the 4k token limit.
Preventing accidents
I thought IMPORTANT: Answer only with JSON and absolutely nothing else. was sufficiently clear, but it’s not. In some edge cases (mostly prompts too obscene to write here), the model follows its own mind and returns something other than JSON. Usually, with some accusations that I shouldn’t be so obscene (don’t judge me, I was testing the limits).
To prevent this from being treated as a filter, each response from the model is parsed into JSON first before being returned to the client. If the response can’t be parsed into JSON, we pull out the old and trusty error message. Filter couldn't be automatically generated. Enter a filter manually. Flawless.
Seriously though, the response was found to be so reliable in our testing that this felt pretty acceptable and covered almost all the edge cases. If you ask it for a joke, it will give you a joke in JSON thought. Not much we can do about that!

Conclusion
There you have it. Taking a moment to reflex on this, it’s shockingly impressive that you can deploy AI-generated filters for a custom syntax in under 24 hours. Although a lot of it still feels like black magic (like the prompt design), it works. It’s a unique tool that opens up opportunities to build better developer products, and you’ll for sure see us leverage it more.
Give it a spin by creating a filter rule within Hookdeck and filter your webhooks in a few words.