![]() Phil Leggetter
Phil Leggetter
Webhooks at Scale: Best Practices and Lessons Learned
Handling webhooks at scale requires a queue-first architecture, idempotent processing, comprehensive observability, and a robust failure recovery strategy with retries, dead-letter queues, and replay. Most teams underestimate this complexity until production breaks. By then, they're dealing with lost events, duplicate processing, and hours of manual recovery.
We've processed well over 100 billion webhooks at Hookdeck and worked with tens of thousands of developers. We've seen the edge cases, the outage postmortems, and the things teams wish they'd done earlier. This article captures the core lessons from that experience, inspired by a talk we're doing the rounds with on Webhooks at Scale talk.
Webhooks: Your First Step Into Event-Driven Systems
Most developers treat webhooks as just another HTTP POST request. But behind that request is something more: an event. A payment succeeded. A subscription updated. A workflow progression.
That means you're working in an event-driven architecture. And that carries the same challenges you'd find in more mature event-driven systems: message ordering, retries, duplicates, failure handling, and more. The difference is, with webhooks, you don't control the producer.
The result? You're dealing with distributed systems problems wrapped in HTTP.
Why Webhooks Are Harder Than They Look
There are three main reasons webhooks are harder to work with than most teams expect:
Event-driven complexity. You face the same challenges as any event-driven system. This includes problems like out-of-order events creating data inconsistencies, duplicates causing unintended side effects, and the need for robust queuing and retry logic to handle failures. Without features like dead-letter queues and proper alerting, it's easy to lose critical events.
You don't control the event producer or the timing. Unlike most queuing systems where you pull messages at your own pace, webhooks are push-based. The sender dictates the delivery schedule and operates independently of your availability. If your system is down or degraded, events will still be sent—there's no pause button. You have to assume they'll keep sending during deploys, incidents, or outages. This lack of control makes decoupled ingestion, queuing, rate limiting, and retries even more critical.
Every provider is different. One provider might retry for 24 hours, another for 5 minutes. Most sign payloads but there's no universally adopted standard and signature verification is opt-in. Timeouts, retry intervals, delivery guarantees—they all vary. So you can't optimize for the best-case scenario. You have to build for the worst one, and assume every provider has edge cases.
At scale, these constraints compound. Let's look at the problems you'll face, and the real-world strategies that teams use to solve them.
Idempotency: You Will Get Duplicates
“An operation is said to be idempotent if performing it multiple times produces the same result as performing it once.”
Webhooks are usually delivered at-least-once. You will get duplicates. You will get out-of-order events. If your logic isn't idempotent, retries will break things.
There's no single right approach to idempotency. But here are three patterns we've seen work in production. Each of these has tradeoffs, and many teams use a combination depending on the endpoint and use case.
Fetch-before-process
In this pattern, the webhook acts as a notification rather than a data source. Instead of trusting the payload, you make an API call to fetch the latest state directly from the provider.
app.post("/api/webhooks", async (req: Request, res: Response) => {
try {
// Verify the webhook signature.
// This is a crucial security step.
if (!verifySignature(req)) {
res.status(401).send("Invalid signature");
return;
}
// The request is authenticated, now get the payload
const payload = req.body;
// The webhook contains a snapshot of the resource
const resourceSnapshot = payload;
const resourceId = resourceSnapshot.id;
if (!resourceId) {
res.status(400).send("Resource ID is missing");
return;
}
// Retrieve the latest version of the resource to ensure you're
// working with the most up-to-date data.
const resource = await fetchLatestResource(resourceId);
console.log(`Processing resource: ${resourceId}`);
console.log(`Resource:`, resource);
// Now you can process the resource, knowing it's the latest version
// ...
res.sendStatus(200);
} catch (err) {
// Handle errors or network issues
console.error("Error processing webhook:", err);
res.status(500).json(err);
}
});
This ensures your logic always processes fresh, consistent data—eliminating concerns about duplicates or ordering. For example, Stripe encourages this pattern by offering "thin events" for certain event types that only include an ID. You then use the ID to fetch the latest subscription, invoice, or customer data.
The tradeoff: this approach makes one API call per event. It's ideal when your logic depends on the latest state rather than full event history, but it can become expensive or infeasible if you're subject to strict rate limits.
For more details and implementation guidance, see our guide on the fetch-before-process pattern.
Insert-or-update with timestamp checks
This strategy relies on conditional writes (like upserts) to ensure that only newer events modify your data. For example, using SQL with a CONFLICT handler and WHERE clause to compare the incoming timestamp against the one stored in your database.
INSERT INTO subscriptions (subscription_id, status, event_timestamp)
VALUES (
'sub_1PWhd8LkdIwHu7ixyvX1ZAbc', -- Stripe Subscription ID
'canceled', -- New status from the webhook
'2025-06-10T16:20:00Z' -- Timestamp of this specific event
)
ON CONFLICT (subscription_id)
DO UPDATE SET
status = EXCLUDED.status,
current_period_end = EXCLUDED.current_period_end,
event_timestamp = EXCLUDED.event_timestamp
WHERE
subscriptions.event_timestamp < EXCLUDED.event_timestamp;
If the incoming event is older, it's ignored. If it's newer, it updates the record. This ensures your system always reflects the freshest state—even if events arrive out of order.
It's efficient and scalable, especially when you need high throughput. But you lose access to historical context and it only works when you store full records with timestamps.
Track processing state per event ID
This approach is useful when you don't store full records, or when side effects (like sending emails or triggering third-party APIs) are involved.
app.post("/api/webhooks", async (req, res) => {
const status = await kv.get(req.body.id);
if (status === "processing") {
res.sendStatus(409);
} else if (status === "processed") {
res.sendStatus(200);
} else {
await kv.put(req.body.id, "processing", { ttl: 60 * 1000 });
await processWebhook(req.body);
await kv.put(req.body.id, "processed", { ttl: 60 * 1000 * 60 * 24 });
res.sendStatus(200);
}
});
You use a separate, ACID-compliant store to track the processing state of each webhook event ID:
- Never seen → process it.
- Currently processing → return an error so it retries later.
- Already processed → skip it.
This model helps you deduplicate webhook processing, even when events don't include timestamps or payloads aren't reliable. It's a good fit for teams needing a generic, low-overhead solution across many types of events.
Queue First, Process Later
Webhooks often arrive in bursts, especially during things like bulk imports, billing runs, or provider outages that trigger mass retries. If you process them synchronously, you'll hit timeouts, dropped connections, or worse: retry storms that cascade into complete system failure.
The solution is to queue everything first. Your ingestion layer should be completely decoupled from your processing logic. Enqueue the webhook, then respond. Process from the queue asynchronously.
Why direct processing breaks at scale
Without a queue, every webhook hits your application server directly. During a traffic burst, say a Black Friday sale or a provider's batch retry after an outage, your server faces simultaneous connections that exceed its capacity. Requests start timing out, the provider retries those failures, and you're in a retry storm where each failure generates more traffic.
A queue-first architecture absorbs the burst. Your ingestion layer does one thing: validate the request and push it to a durable queue. It responds immediately, so the provider sees success. Your processing workers then consume from the queue at whatever rate your infrastructure can handle, using rate limiting to protect downstream services.
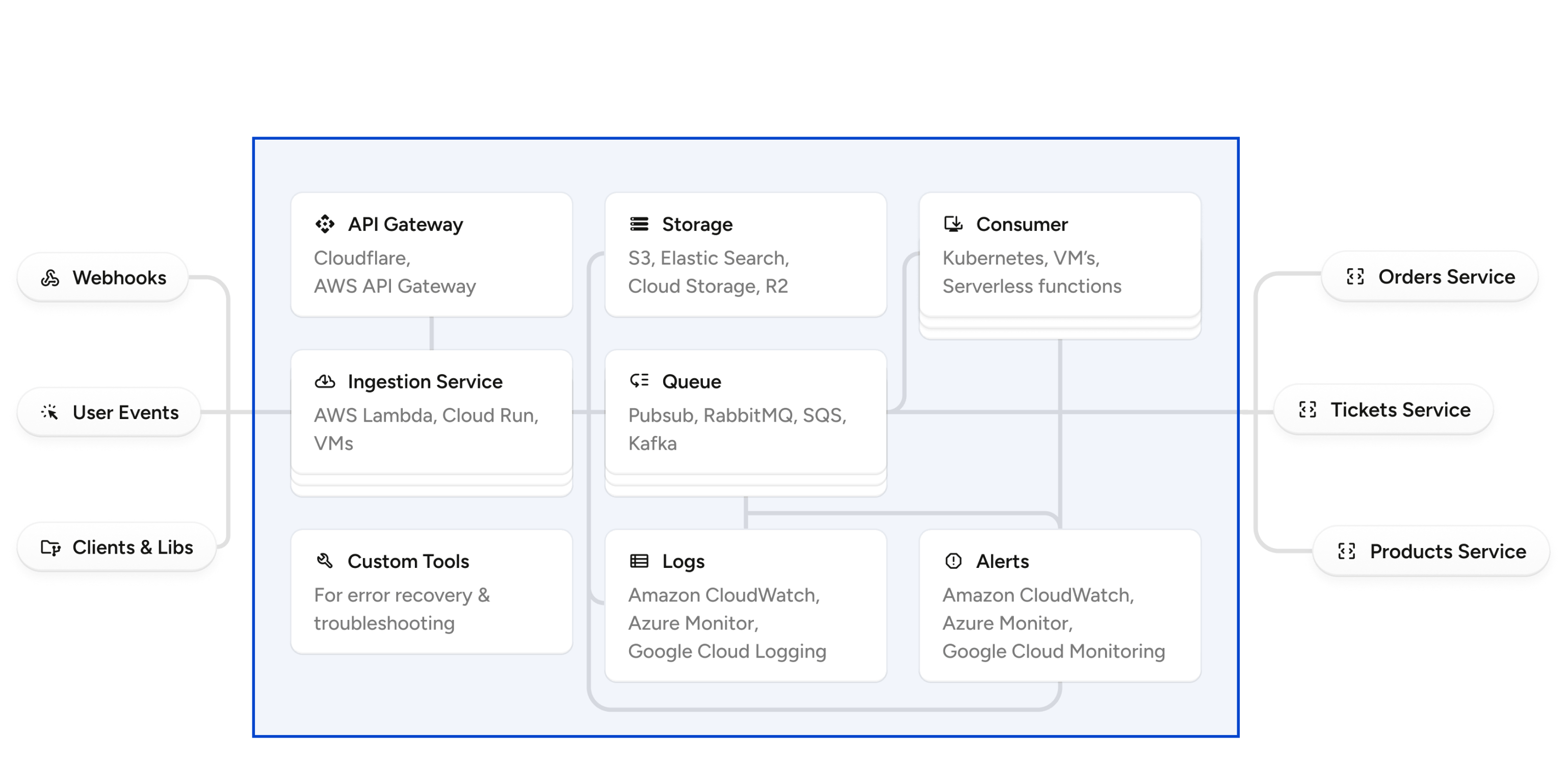
This buys you control. You can throttle processing, prioritise events, and retry safely. But you need to monitor for back pressure.
Understanding and Managing Back Pressure
Back pressure happens when your queue grows faster than you can process it. This creates delays and can lead to stale data or retry overload.
To stay ahead of it, monitor these key metrics:
- Queue depth: How many events are waiting to be processed.
- Max age: How old is the oldest event in the queue.

At Hookdeck, we combine these into a single metric: estimated time to drain. It helps us (and our users) understand whether the system is keeping up or falling behind.
Failure Recovery: Retry, Replay, or Reconcile
Things fail. Workers crash, deploys break, databases go down. When that happens, you have three strategies, and most mature systems use all of them:
Retries with backoff
Automatic retries handle transient failures: a momentary network issue, a brief database lock, a container restart. Configure exponential backoff so you're not hammering a struggling service. But retries alone aren't enough: they handle short-lived problems, not extended outages.
Dead-letter queues and event replay
When retries are exhausted, events shouldn't silently disappear. A dead-letter queue (DLQ) captures events that failed all retry attempts, giving your team a path to investigate and recover. In Hookdeck, Issues serve this role — tracking failed events and alerting your team. Once the root cause is fixed, you can replay failed events in bulk to recover without data loss.
Reconciliation as a safety net
For critical data, build reconciliation tooling that fetches current state from the source of truth and rebuilds downstream systems. Stripe makes this easier with their Events API. Other platforms may require more custom tooling. Build the reconciliation tooling before you need it — teams often realise this too late.
The key insight: retries handle minutes of failure, replay handles hours, and reconciliation handles everything else. Layer all three for comprehensive webhook reliability.
Observability: Know What You Received
It's easy to lose track of what events you received, what failed, and why. Especially during incidents.
That's why centralised event logging matters. Store every webhook, its payload, metadata, and response. Pipe it to Elasticsearch or another log store. Build tools to query by customer ID, event type, or delivery status.
Key metrics for webhook observability at scale
At scale, you need more than logs. You need metrics that tell you whether the system is healthy right now:
- Delivery success rate: What percentage of events are delivered successfully? A rate below 99% warrants investigation.
- Retry rate: A rising retry rate is the first signal of destination stress — before failures start.
- Queue depth and drain time: How many events are waiting, and how long until the queue is empty? Growing queue depth means your processing can't keep up.
- Response latency (p95, p99): Latency spikes precede failures. Track percentiles, not just averages.
- Error rate by destination: Isolate which services are struggling rather than treating all failures as one problem.
Set alerts on these metrics. The goal is to detect and respond to problems before they cascade into data loss or customer-facing failures.

This isn't just for debugging. It's essential for support, audit, and incident response.
The Shift to Event Destinations
Until recently, webhooks were the only option. But that's changing.
Platforms like Stripe, Shopify, and Twilio now support direct delivery to message buses (like Amazon EventBridge, GCP Pub/Sub, or Amazon Kinesis). We're calling these event destinations. Instead of sending you a webhook, they push to your event infrastructure directly.

This avoids a whole class of problems: enforces authentication, ingestion scaling, a layer of HTTP infrastructure including API gateways, load balancers, and webservers. And it shows that platforms are taking event delivery more seriously. These features didn't exist a few years ago.
At Hookdeck, we sponsor the Event Destinations Initiative to help define a shared spec across platforms. We also open sourced Outpost, a reference implementation that supports webhooks, queues, and popular brokers and event gateways.
What is an Event Gateway?
An Event Gateway is a new category of infrastructure. If you think of an API Gateway as the control point for synchronous traffic, an Event Gateway plays the same role for asynchronous traffic.
It handles:
- Ingestion
- Queuing
- Throughput control
- Filtering and routing
- Transformations
- Observability
- Retries and delivery guarantees
At Hookdeck, we've built our own Event Gateway product, and we're seeing other event gateways emerge in the space. The category is still taking shape, but the need is clear: webhook and event infrastructure is becoming core infrastructure.
How We've Solved Webhooks at Scale Problems at Hookdeck
After processing over 100 billion webhooks and learning from thousands of production incidents, we've built these solutions into Hookdeck's Event Gateway. Here's how we address each challenge:
- Burst Protection: Our queue-first architecture automatically scales to thousands of events per second. During Black Friday 2024, we helped customers process 10x normal traffic without a single timeout.
- Provider Chaos: Instead of building custom logic for each provider's quirks, Hookdeck normalizes delivery with adaptive rate limits and retries that work across Stripe, Shopify, GitHub, and hundreds more.
- Incident Recovery: Every webhook is logged with full payload and headers. When things go wrong, you can search by any field, replay failed events in bulk, or route them to dead-letter queues, turning hours of recovery into minutes.
- Real-time Visibility: Monitor queue depth, processing rates, and error patterns in real-time. Set alerts on back pressure before it becomes an incident.
Whether you're processing thousands or billions of webhooks, Hookdeck provides the infrastructure so you can focus on your business logic instead of webhook plumbing. Try Hookdeck free to see how it works.
Watch the Full Talk
Want the deeper dive with demos? Watch the original Webhooks at Scale talk by Alex, CEO at Hookdeck. It walks through real examples of handling idempotency, webhook ingestion architecture, queue back pressure, filtering, retries, and more.
Final Thoughts
Webhooks are simple until they're not. Once you grow beyond a certain point, the cost of poor webhook handling shows up in developer time, incident response, and customer experience.
Whether you use Hookdeck or build your own solution, these best practices can help you stay ahead of scale. For most teams, the engineering cost of building and maintaining webhook infrastructure far exceeds the cost of a managed solution, especially when you factor in incident response, on-call burden, and the opportunity cost of not building product. As the ecosystem evolves, with event destinations and event gateways, there are more options than ever to get webhook reliability right.
Got thoughts, stories, or questions? I'd love to hear them.